I am currently writing my Master’s thesis at the Accelerated Big Data Systems research group of TU Delft which researches how next-generation hardware can accelerate big data analytics. They have, for example, developed Fletcher, a platform that integrates FPGA accelerators with Apache Arrow, a language-independent columnar memory format. I research in my thesis how Apache Spark queries can be partly executed on Fletcher without having the users to modify their code.
Simply spoken, a field-programmable gate array (FPGA) is a chip that allows the user to reprogram its internal circuit. Compared to regular CPUs, many data processing tasks can be executed on FPGAs faster and/or with lower energy consumption. Unfortunately, programming an FPGA is a complex task, and even “compiling” a new circuit is very time-consuming.
Therefore, in my thesis, the challenge is not to generate the FPGA circuit which might be the first assumption. Instead, my goal is to identify parts of Spark queries for which already compiled FPGA accelerated versions exist. Furthermore, I investigate Spark’s architecture to identify extension points for modifying the data processing flow so that it can be (partly) executed on Fletcher. I evaluate the technical feasibility of such an acceleration and implement a prototypical scenario to evaluate the performance increase.
For my use-case, the most important component is Spark SQL, a module that enables the user to write declarative queries. The Catalyst engine in the background understands then the purpose of the query and can optimize it. As the following image shows, this engine has multiple query planning phases and allows me to extend with my own code.
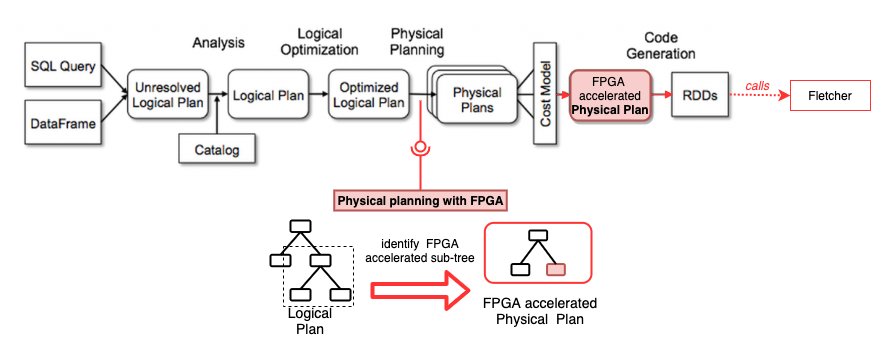
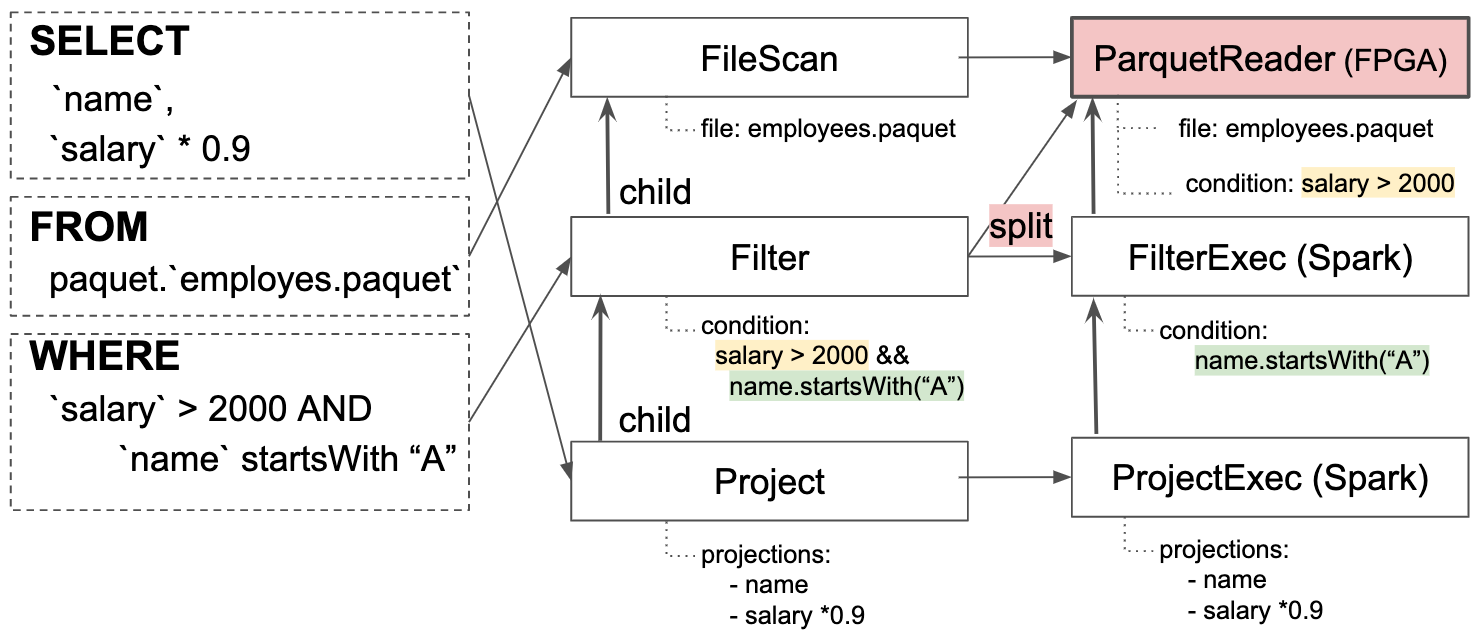
For implementing a prototypical scenario, I highly depend on the availability of accelerated FPGA modules. Therefore, my supervisors and me agreed on accelerating the reading of parquet files. The following pictures demonstrates the change of the execution flow for a simple query.
The source code written in Scala and C++ of my current implementation can be found on Github.